Well..it’s true. The PHP glob() function is a big dinosaur, memory eater and speed blow upper (if that can be said). So let’s test the glob() function against some other alternatives.
I have recently had to detect duplicated/missing files comparing two directories in a set of 80.000 files and I used the PHP glob() function. 80k is a reasonable number for a local machine. But later I had to deal with 800k and that is really a lot if you don’t do things the right way. So I had to try some other alternatives.
I had to do some benchmarking in the area and I used a set of 25.000 images and another folder with 10.000 random duplicates. I think this is a reasonable number to see any differences in the final result.
Here are my approaches in my intent of testing the duplicate file detection
So for first test I runned the function as it is. You can see the entire function n my previous article:
|
1 |
$files = glob( $dir[1]."/*".$ext); |
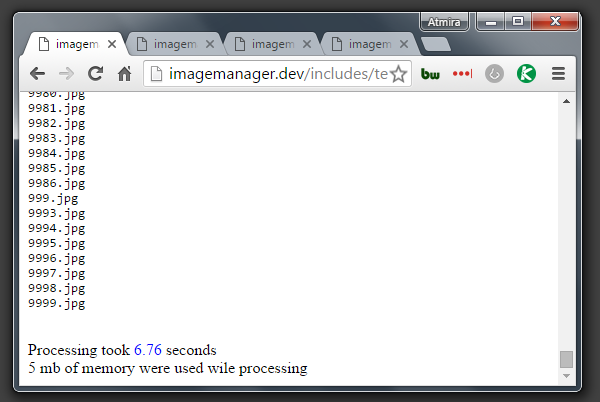
Processing took 6.76 seconds and 5 mb of memory.
Second I used the GLOB_NOSORT . This can make a significant improvement if you do not care about the file order. GLOB_NOSORT param returns files as they appear in the directory which means no sorting. When this flag is not used, the path names are sorted alphabetically
|
1 |
$files = glob( $dir[1]."/*".$ext, GLOB_NOSORT ); |
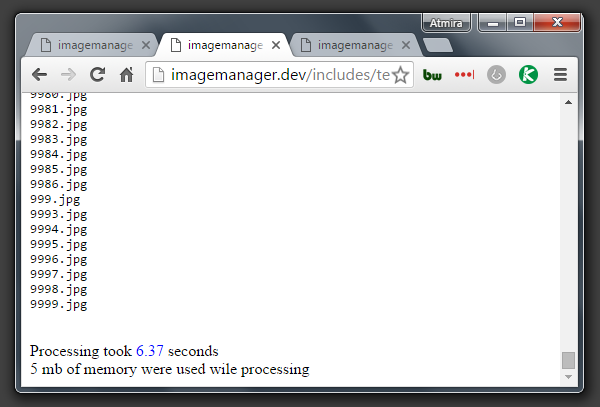
Processing took 6.37 seconds 5 mb of memory.
I have done this tests using the function I described in the previous article and the concept is quite simple. Buid an array of all files in folder dir1 and see if the files exists in dir2. Note that time may vary depending of the CPU usage at the moment of the test an that it is exponential depending of the files quantity. You can take a look at the function here. I had commented out tbe part that renames or delete the files and felt just the on-screen messaging.
Of course I can always search dir2 instead of dir1 . It is a good point if you know what folder will have less files, you can choose to start from there. It is very logical that if the folder will have less file, the function will spend less time to build the array in memory. But this is not of my interest right now in the process that I am doing, since dir2 will have more and more images as opposite as dir1 .
So for now I don’t think there is much I can do. glob() function builds an array with all files that are in the specified folder and it has to do it no matter what.
It could be a lot faster if it didn’t try to build the array and just check for the duplicated files on the fly. This could be a good approach, so let’s look in the PHP arsenal and see what else we can find.
How to use readdir() to search for duplicate files in distinct folders
The PHP readdir() function returns the name of the next entry in a given directory. The entries are returned in the order in which they are stored by the filesystem. This seems to be very similar to glob() , but it doesn’t store the filenames in memory as an array.
So let’s build a little function using readdir() to search through the folders for duplicated files.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
function simple_compare_folders($dir) { echo "<pre>"; if ($handle = opendir($dir)) { while (false !== ($file_name = readdir($handle))) { echo "$file_name<br />"; } closedir($handle); } echo "</pre>"; } |
And let’s do some benchmark on it 😀
Waw…god damned…this is awesome. If you blink you won’t see it. This is f*** real speed. But hey, this only prints the files, and not comparing them to come up with the duplicated ones. Well, let’s add the fancy stuff from our first function and see how it does. Hands on work:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
/** * @param array $dir: this is an array with your custom paths * @param string $ext: File extension * @param boleean $action: flase, move of delete. If false no action will be taken and files will be printed on screen. * @param boleean $output: If false, no message will be output to screen. * @return string */ function compare_two_directories_readdir($dir, $ext="jpg", $action = false, $output=true) { if($output) echo "<pre>I found this duplicate files:<br />"; if ($handle = opendir($dir[1])) { while (false !== ($file_name = readdir($handle))) { $ext = strtolower(end(explode('.', $file_name))); // Check for extension if ($ext == $ext_ck) { // check if file exists in the second directory if(!file_exists($dir[2]."/".$file_name)) { if($output) echo "$file_name"; if($action == 'move') { rename($file, $dir[3]."/".$file_name); // move the image to folder 3. if($output) echo " <span style='color:green'>moved</span> to ".basename($dir[3])."<br />"; } elseif ($action == 'delete') { unlink($file); // just delete the image if($output) echo " <span style='color:red'>deleted</span><br />"; } else { if($output) echo '<br />'; } } } } closedir($handle); } if($output) echo "</pre>"; } |
And here it is. Nice and clean. Let’s do some benchmark on it and hope for the best.
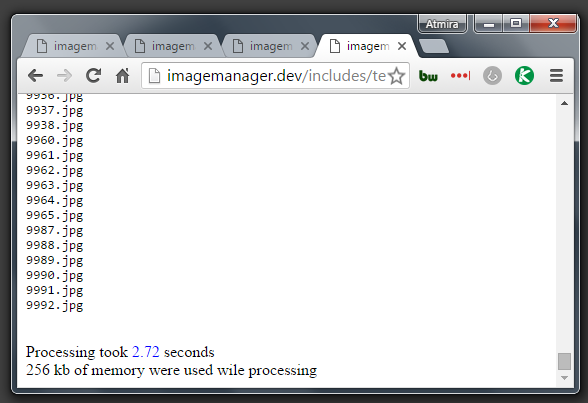
2.72 seconds …well how about that? I saved more than half of the time just using readdir() function. That’s more like it. And take a look at the memory usage! It dropped down from 5MB to 256Kb, isn’t that great or what? Try to apply this algorithm to 800k instead ok 25k of files…This is really a significant improvement.
At this point I think there is no need to do further testing on this 2 functions although I agree that depending on the case, there is not possible to user readdir() and that glob() could be your only approach.
Conclusion: readdir() … you rock!!
We have speed up the process a lot but I would like to try some other things and see if there are ways to make the code a little bit faster. After a little more testing and after introducing some break points I have noticed that the slower part, is the one that checking if the file_exists in the second folder and it eats up more than 2 seconds. This is like 90% of time is used here. How can we speed this up?
How to speed up the PHP file_exists() function …dead-end?
This is quite a rough road. There are lots of people saying that there is not much you can do about it. But some say that thinks speed up if you use is_file() instead of file_exists() . Well maybe on millions of files or on different folder structure. I’ve seen no change on my 25k set of JPEG images.
I have also tried using clearstatcache() with no better result in my case.
But then I found this so called stream_resolve_include_path() . In the PHP manual they say it resolve the filename against the include path according to the same rules as fopen()/include . The value returned by stream_resolve_include_path() is a string containing the resolved absolute filename, or FALSE on failure.
Could stream_resolve_include_path() function , be the holy grail?
So everything should work just fine. In case it finds the file, will return a string. A string is always evaluated to TRUE by the if statement, so we’re good on this. An in case the file is not found will return FALSE witch is OK.
Let’s do some benchmark testing with stream_resolve_include_path() and see if we can replace file_exists() with it.
|
1 2 3 4 5 6 |
// just replace this next line if(file_exists(($dir[2]."/".$file_name)) // with this next line. Simple as that if(stream_resolve_include_path ($dir[2]."/".$file_name)) |
And here is the result of testing.
I think there is really no need to tell you that this is quite it for now. We have compared 25k of files against other 10k and all this in 1.35 seconds. This really is speed. Did I told you that images are not quite small? There are 2.61GB of images to compare against other 1.08GB.
1.35 seconds to compare more than 3GB of files is really a good time. It is 6 time faster than the gob() and file_exists() functions.
I have to say that I run this on a local machine, and it is more important to me to get the job done then get a lower loading time. So seconds are ok for me and I am not really interested in microseconds.
File check comparison benchmark testing – the final loop
OK, just for the record and to see some big data processed, I will do some benchmark only on this 3 PHP functions ( is_file(), file_exists() and stream_resolve_include_path() ) and test them on a 1 million loop. I will first test with an existent file and then with a file that doesn’t exists.
Here is my little function that does the testing on this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
function do_benchmark( $file ) { $funcs = array('is_file','file_exists', 'stream_resolve_include_path'); $run = 1000000; $stats = '| '; foreach ( $funcs as $func ) { $go = microtime(true); for ( $i = 0; $i < $run; $i++ ) $func($file); $stats .= "$func = " . number_format( (microtime(true) - $go), 5) . " | "; clearstatcache(); } return $stats; } $ok_file = dirname(__FILE__)."/icon.gif"; $no_file = dirname(__FILE__)."/none.png"; echo "<pre>" . do_benchmark($ok_file) . "\n" . do_benchmark($no_file) . "</pre>"; |
And here are the results on this: It is really surprising. I think this speaks for itself
|
1 2 3 4 5 |
// this is when file is in place | is_file = 0.39600 | file_exists = 28.20900 | stream_resolve_include_path = 1.46400 | // this is when file is not found | is_file = 32.74600 | file_exists = 31.56300 | stream_resolve_include_path = 31.15000 | |
This explain why my previous test returned better results using stream_resolve_include_path(). The part that I do not understand is why is_file() did not make the code faster in the first place. For this test a used a really small image and then I repeat the test using a large image, but it seems that the file size does not influence the final result.
So what do you think? If you know about some other alternatives on this just let me know. I would really die to test them out.
why glob seems slower in this benchmark? because glob will do recursive into sub dir if you write like this “mydir/*”.
just make sure there is no any sub dir to make glob fast.
“mydir/*.jpg” is faster because glob will not try to get files inside sub dir.